Slashing LLM Costs: Why We’re Moving to TOON for Heavy Payloads

TL;DR
We’re spending too much on JSON overhead in LLM calls. By switching to TOON (Token-Oriented Object Notation) at the LLM boundary only, we can cut token usage by 40–60% for structured data without sacrificing accuracy, compatibility, or developer sanity.
Last month, while reviewing our AWS bills for a marketing automation project, I noticed a 40% spike in OpenAI costs. Traffic was flat. The model hadn’t changed. Something else was leaking money.
The culprit turned out to be surprisingly mundane: JSON bloat.
As we started sending larger payloads of customer engagement records, we weren’t just paying for data, we were paying for thousands of redundant curly braces, quotes, commas, and repeated keys. At scale, that overhead adds up fast.
That’s when we introduced TOON at the LLM boundary.
What is TOON?
TOON (Token-Oriented Object Notation) is a lightweight internal serialization convention we use when sending structured data to LLMs. It is not a formal standard and does not replace JSON across the system.
Think of TOON as a prompt-optimized, schema-once format somewhere between:
- YAML (human-readable)
- CSV (row-efficient)
- A database table (explicit schema)
The goal is simple: maximize semantic density per token for LLM tokenizers.
Unlike JSON, TOON declares the schema once and then sends only values eliminating repeated keys and punctuation-heavy syntax that LLMs don’t need.
The Efficiency Gap: JSON vs. TOON
Here’s a real example from our customer meeting data.
Standard JSON (156 tokens*)
{
"meetings": [
{ "id": 1001, "customer": "Sandhu Santhakumar", "type": "consultation", "status": "completed" },
{ "id": 1002, "customer": "Anand V Krishna", "type": "follow-up", "status": "scheduled" },
{ "id": 1003, "customer": "Vinu Varghese", "type": "consultation", "status": "cancelled" }
]
}Same Data in TOON (78 tokens*)
meetings[3]{id,customer,type,status}:
1001,Sandhu Santhakumar,consultation,completed
1002,Anand V Krishna,follow-up,scheduled
1003,Vinu Varghese,consultation,cancelledComparison
| Format | Token Count* | Readability | Cost Impact | Why |
|---|---|---|---|---|
| JSON | 156 | High | Baseline | Keys repeat; punctuation-heavy |
| TOON | 78 | Medium | ~50% lower | Schema once; value-only rows |
*Token counts measured using cl100k_base (GPT-4 / GPT-4o). Actual counts vary by model and tokenizer, but relative reductions remain consistent.
Why Not CSV / Protobuf / Avro?
This question always comes up, so let’s address it directly.
- CSV lacks explicit schema binding and is fragile in prompts without strict instructions.
- Protobuf / Avro require binary encoding and schema tooling excellent for service contracts, overkill for prompts.
- TOON is self-describing, deterministic, prompt-friendly, and has zero external schema dependencies.
TOON isn’t competing with serialization frameworks. It’s optimized specifically for LLM ingestion, not inter-service communication.
Why This Matters for Xminds
Let’s put real numbers on it.
- Model: GPT-4-turbo ($0.01 / 1k input tokens)
- Current volume: 10M tokens/day
- Current cost: $100/day (≈ ₹8,330/day)
- With TOON (~40% reduction): $60/day (≈ ₹5,000/day)
- Annual savings: ₹12.15 Lakhs (~$14,500 USD)
And this is just one feature. At organization scale, this becomes cost governance not micro-optimization.
The Key Idea: The “LLM Boundary”
We do not replace JSON everywhere.
Databases, APIs, and frontend apps remain JSON-native. TOON exists only at the LLM boundary, the moment data enters an LLM call.
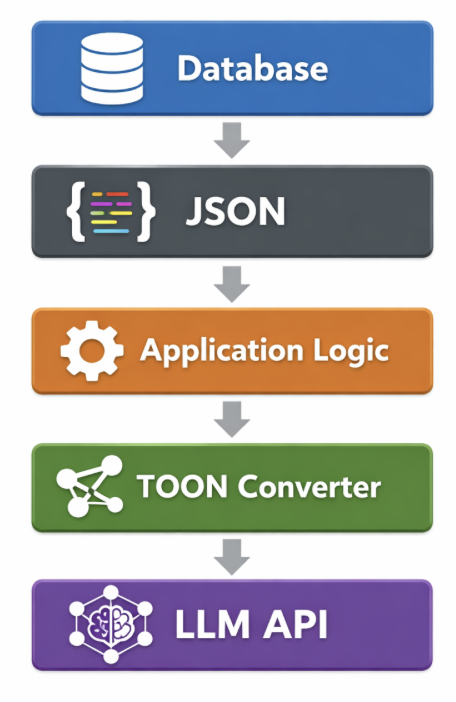
This keeps optimization isolated, reversible, and safe.
Implementation & the “Golden System Prompt”
import { encode } from "@toon-format/toon";
const TOON_SYSTEM_PROMPT = `
Data is provided in TOON (Token-Oriented Object Notation).
Rules:
1. Header format: name[count]{key1,key2,...}:
2. Each subsequent line is a record.
3. Values map strictly to header key order.
4. Do not infer, reorder, or add fields.
If you output structured data, use the same TOON format.
`;
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: TOON_SYSTEM_PROMPT },
{ role: "user", content: encode(customerData) }
],
temperature: 0 // Eliminates stochastic reordering & structural hallucinations
});Temperature = 0 is non-negotiable.
Any randomness risks reordered columns or hallucinated fields.
When TOON Shines (and When It Doesn’t)
Ideal Use Cases
- Uniform arrays (logs, transactions, products)
- RAG metadata and retrieval contexts
- High-volume endpoints (1,000+ LLM calls/day)
- Cost-sensitive inference pipelines
Stick to JSON When
- Data is deeply nested (5+ levels)
- Objects have irregular or optional keys
- Data is client-facing or externally consumed
TOON isn’t about clever formats, it’s about respecting how LLMs tokenize data.
By treating the LLM boundary as a first-class architectural concern, we:
- Reduce costs materially
- Improve inference speed
- Keep the rest of the system untouched
The format takes 20 minutes to learn. The habit shift saves lakhs every year.
That’s a trade-off worth making.
Author

Related articles

